Tokenization is a method of substituting sensitive data with non-sensitive placeholders called tokens. These tokens are swapped with data stored in relational databases and files. The tokens are commonly random numbers that take the form of the original data but have no intrinsic value. A tokenized credit card number cannot be used (for example) as a credit card for financial transactions. Its only value is as a reference to the original value stored in the token server that created and issued the token. In data transferring, as the transmission process and storage process has the danger of personal information breach, by using token data (and not the original data), it can protect personal information.
Furthermore, tokens can follow the same format of the original personal data for easy application in existing business systems. For example, the token of a 16-digit credit card number uses the combined data of a 12-digit random number and 4 numbers from the credit card number. If the business system was organized in 16 digit card numbers, the replaced 16 digit token would be easily exchanged as it is in the same format. Typically, the token will retain the last four digits of the card as a means of accurately matching the token to the credit card owner.
Demand for protecting personal information in business systems increased due to the effectuation of personal information protection laws. Tokenization became known popular as a method of data protection that allowed data properties (length, form, data type) to be maintained while securing it.
Let’s refer to the credit card industry as an example in order to examine composition of tokenization.
Composition of Tokenization

If a consumer presents the credit card in the store (1), the card reader (POS; Point Of Sale) transmits the credit card number to the token server through an encrypted communication channel.
The token server which receives the credit card number generates the token data (substitute for the credit card number), saves a pair of the token data & credit card number in the token storage (2), and shows the token data to the card reader in the store (3).
The card reader delivers the card number to the application server (4), and the application server uses the token number as a substitute for the credit card number when handling data (5).
If the original card number (connected with the token number) is needed, it can be verified by requesting it to the token server. (6, 7, 8, 9)
A big advantage of tokenization is that the credit card number doesn’t need to be saved in the card reader which can leave it vulnerable. Moreover, since the personal information saved in the dispersed storage can be managed integrally, security effort only needs to be focused on the token server. On the other hand, serious damages could occur if the token servers are vulnerable and information is leaked as personal information is converged in the token server.
Stability of Tokenization
Tokenization seems like the ideal model to protect data; however it is only substituting data for tokens. Therefore, security and stability in the token generation process is important. While tokenization allows for data properties to be maintained, some corporations choose to generate tokens by using the Weak Pseudo-Random Number Generator (WPRNG) which is considered insecure. WPRNG employs a simple conversion that does not use an encryption key. Not only is it unstable, it can also produce duplicate random numbers, which allows personal information to be analogized. Some corporations will store tokens generated in this manner with personal information in the token server segregated from the DB server and boast the security strength of the Token Server, but they often neglect the verification of the token’s stability and security of the DB server itself.
If so, what’s the method of applying the same concept of tokenization simultaneously by using safe technology? The solution is to apply Format Preserving Encryption (FPE). FPE is an encryption algorithm best known to secure data and still maintain its properties.
Tokenization and FPE
Both tokenization and FPE allows the changed data to look like the original value in data type and length. This is highly sought after as these properties will enable it to travel inside most applications, databases, and other components without modifications, resulting in greatly increased transparency. This will also reduce remediation costs to applications, databases, and other components where sensitive data lives, because the tokenized data will match the data type, length and format of the original, and will better protect data as it flows across systems due to the higher level of transparency to business rules and formatting rules.
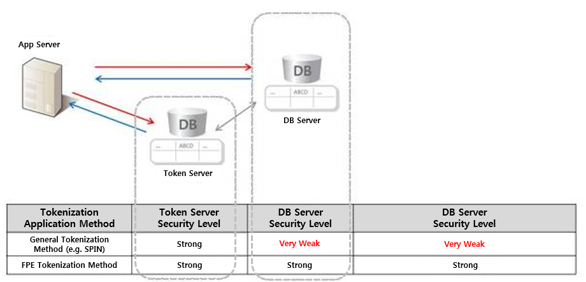
While tokenization and FPE may be similar on the surface, they are fundamentally different. While both allow the preservation of the format of the data, they are not the same thing in that tokenization is based on randomness, not on a mathematical formula. Format Preserving Encryption is a method of creating tokens out from sensitive data. But format preserving encryption is still encryption – not tokenization. With tokenization, the token cannot be discerned or exploited since the only way to get back to the original value is to reference the lookup table that connects the token with the original encrypted value. There is no formula, only a lookup. However, a combination of a weak number generator and weak DB security level can undermine its full security potential.
Format preserving encryption is a way to avoid re-coding applications or re-structuring databases to accommodate encrypted (binary) data. Both tokenization and FPE offer this advantage. However, encryption obfuscates sensitive information, while tokenization removes it entirely (to another location). With FPE different encryption keys can be used on different personal information, which allows for tighter security. Additionally, since personal information can be decrypted from the token and encryption key, there is no need to save, store, or manage tokens and personal information on a separate token server. As FPE is based on block encryption, it is applied in the same operating mode as block encryption, and thus offers the same security level. Simply put, FPE is taking the idea of tokenization and using it with an encryption algorithm with encryption keys and removing the secondary token servers.